DPLA Strawman Technical Proposal
Published: 2012-01-23 13:56
Collection Achievements and Profiles System and DPLA Crawler Services
This is a quick strawman proposal for what the Digital Public Library of America should build as the first parts of a generative platform. This document is not in a finished state, but just as the DPLA has been good at opening up its process with the Beta Sprint, I wanted to release this document early even in this unfinished state.
I attended the December DPLA Technical Workshop in Cambridge and was inspired by the discussion there. I hope that this document makes it clearer some of the approaches I and others at that meeting were advocating. I shared this with the DPLA Interim Development Team a couple of weeks ago, and now that development has started I thought I would share it here as well.
While the first iteration of the DPLA platform may be set and on its way, I still wanted to share one vision of what a generative platform for aggregations might involve. The main point is to get the DPLA to the aggregations they likely need to present at some point. This document leaves aside the question of whether creating aggregations is a good idea. The desire to create aggregations is a big, often unquestioned, assumption of big digital library projects. I think what is set out below is one simple architecture for accomplishing aggregations in a very Web-centered way while potentially having more reuse outside of just aggregations.
Introduction
This proposal gives a high-level overview of one possible DPLA technical architecture. This gives the idea of what a beginning of a scalable, extensible DPLA platform could look like. The architecture starts with a foundation in the distributed digital collections which already exist on the Web. The platform set out here works with the way the Web works while allowing the DPLA to meet its goals. As a result it will also help cultural heritage organizations to meet their goals for greater discoverability of their collections.
Collecting and keeping track of the those existing collections is the job of the Collection Achievements and Profiles System (CAPS). The metadata CAPS collects can be reused to do focused crawls of digital collections through a DPLA Crawl Service. The results of those crawls can be analyzed, and the data used for a variety of applications including topical or format aggregations, mashups, visualizations, and other internal and external tools.
This architecture can be summarized through the following diagram.
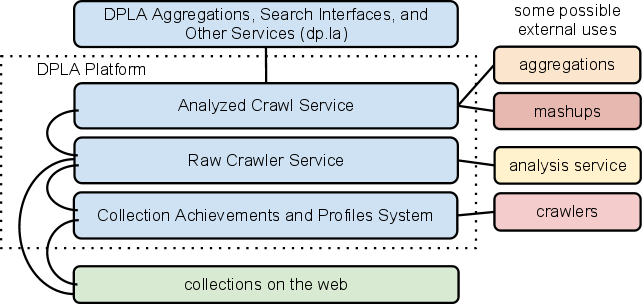
The rest of this document begins with an overview of how these major components fit together. It then goes into more detail about the architecture and technical components required to implement the two major pieces of this platform:
- Collection Achievements and Profiles System
- Crawler Services: Crawler Services are further divided into the Raw Crawler Service and the Analyzed Crawl Service.
Architecture Overview
The foundation for the DPLA platform would be the distributed collections on the Web. The DPLA can help make these distributed collections more discoverable on the open Web and enable new services. A user with a browser can already enter the address for these digital collections and get something useful back. In this scenario any digital collection on the Web can be a part of the DPLA. The collection (and hosting institution) is not required to implement any new metadata format, gateway, or API. The existing published HTML pages are enough to gain the initial benefits of a DPLA. Collections can choose to adopt other Web standards or provide more information on their collections to gain more of the benefits of the DPLA and the Web at large.
The technical barriers to entry into the DPLA are purposefully low to maximize participation. The DPLA has an opportunity to be a truly big tent approach to solving the problems of making America’s cultural heritage accessible and discoverable. When suggesting digital collections adopt standards or make changes, this proposal gives preference to asking digital collections to optimize for the Web for broad applicability. The technical decisions made here always choose what would make the system simpler and easier for producers of digital collections over what would be easier for the DPLA or other aggregators.
The Collection Achievements and Profiles System (CAPS) is an editable directory of Web-accessible digital collections. In its most basic form Collection Profiles hold the name and URL of digital collections. Achievements are a way to expand Collection Profiles through gathering discrete pieces of data about collections and their institutions. In order to validate various Achievements, CAPS can request pages and resources from a collection Website. Full Collection Profiles with all completed Achievements are available through a simple API.
The Raw Crawler Service finds new collections to crawl through CAPS. The Raw Crawler Service can then launch crawls of a collection Web site. The raw crawl data can be made available to external developers who want to do their own analysis of the raw crawl data and build new services.
The Analyzed Crawl Service makes use of the raw crawl data to extract data and text from pages. CAPS can use this data to perform work like validating Achievements, assigning automated tags to collections, and confirming the health of Web sites. The DPLA could use this analyzed crawl data to create various aggregations, search interfaces, and other services for digital collections that are only possible through having this central data store. External developers could access the analyzed crawl data to create their own aggregations, mashups, and other services.
The DPLA can create a generative platform through using the existing digital collections on the Web and adding value. Each major component of the DPLA platform can make its data available to the world to enable the creation of novel new services and new creative works.
Collection Achievements and Profiles System (CAPS)
The first component that the DPLA could build is a Web application which allows for collecting basic information about collections. We call this the Collection Achievements and Profiles System (CAPS). DPLA Collection Profiles provide a mechanism for the DPLA to host a centralized Web-based, editable directory of collections on the Internet. DPLA Collection Achievements provide a mechanism for progressively expanding Collection Profile descriptions, promote standards adoption, validate adherence to standards, and progressively engage the community. While the initial barrier of entry is low, CAPS encourages digital collection managers to adopt standards that benefit the discoverability of their collections and benefit the goals of the DPLA.
Before reading the following technical aspects of the CAPS proposal it would be best to familiarize yourself with the Collection Achievements and Profiles System documentation. This detailed documentation was done as part of a DPLA Beta Sprint submission, and it forms the initial thinking for this work, including a narrative, wireframes, and Achievement ideas.
Technical Components of CAPS
CAPS can be modeled with the following diagram. Elements in blue are managed by the DPLA. Other colors refer to various external contributors and consumers.
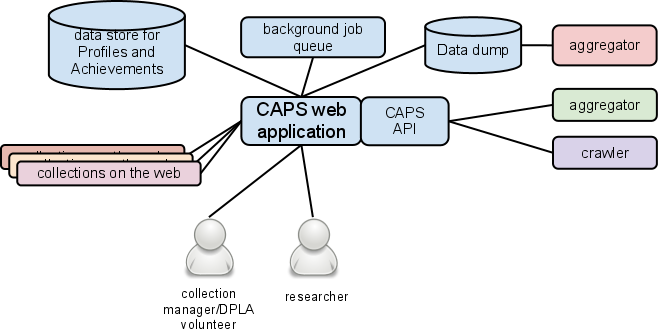
Following is a description of the major components of CAPS.
The CAPS Web application allows for editing and managing Collection Profiles and Achievements (information about collections on the Web). Collection managers and DPLA volunteers can create and update Profiles and Achievement data through Web forms. A researcher looking for collections (on a particular topic, in a geographic region, or other relevant facet) could also discover collections and see all information about the collections.
The Web application can request pages or other resources for a collection on the Web using the stored URL. For instance when a Collection Profile is first created the URL is validated for being well-formed and then the page is requested to check that it returns a 200 OK status code. Other Achievement validations could also request information from the site (e.g. robots.txt, sitemap). To insure that the CAPS application returns a timely response for editors, CAPS can defer some of these longer running processes and validations to a background job queue.
CAPS would require a persistent data store for Collection Profiles and Achievement data. Periodically a data dump of all data could be created for consumption by external aggregators, crawlers, and service providers. Access to all of the data or searches for slices of data would be available through a Web API. Consumers of the API could be aggregators, crawlers, and other service providers. Through the API the DPLA could also provide other services like aggregated sitemaps. Having multiple ways (data dump and API) for accessing the data, lowers the barrier for developers both internally and externally to build new and interesting applications.
Standards through Achievements
Through Achievements the DPLA can encourage the use of various standards which can make Collection Profiles more useful.
Initial effort can be put into Achievements which can be automatically detected, therefore requiring minimal effort from contributing collections. The DPLA can adopt Achievements for Web standards that will improve the discoverability of collections on the open Web. For instance it is possible to automatically check whether the site allows for crawlers (robots.txt) and has a sitemap of the most important pages to crawl (sitemap protocol). When digital collections implement these kinds of standards it benefits all consumers of digital collections resources, including the DPLA and search engines.
These same Achievements will have interconnections with the rest of the architecture laid out here. For instance automated Achievement validations can require analyzed crawl data to be confirmed.
Other Achievements which would benefit libraries and museums could also figure prominently. Knowing the hours of operation and geographic location of the access point to the physical collections, could help encourage visits to a library or museum. CAPS can provide the data to start making connections between the digital and the physical.
Since Achievements add a named, small, discrete piece of information to a Collection Profile, the code required to implement an Achievement is relatively small and self-contained. The starter set of Achievements could create a basic functional system that can be delivered quickly to help bootstrap the rest of the DPLA effort. Achievements can be incrementally added over time. Communities and developers could work to create and incubate new Achievements around new standards before they become part of the DPLA core platform. Achievements are another way in which the DPLA could continue to spur innovation around digital collections standards and services.
Crawler Services
Crawler Services are responsible for coordinating robots to crawl digital collections sites, analyzing the data, and making it available.
Benefits of Crawler Services
Rather than using new or existing niche library protocols, the DPLA could make use of common, ubiquitous Web protocols and standards. Encouraging standards (through Achievements) that help the DPLA do its work to crawl digital collections, will also aid the discoverability of digital collections on the open Web.
The data created through the Crawler Services is important background information for CAPS to validate some Achievements. Certain standards which the DPLA may want to promote through Achievements, would require requesting multiple pages from a collection. For instance validating a sitemap could involve requesting each of the listed URLs. The resulting data could be used to confirm the presence of listed URLs.
Analyzed crawl data could form the basis of various DPLA aggregations and services. Making this data available will also encourage other developers to create applications using digital collections.
Architecture of Crawler Services
Crawler Services can be split into two interrelated, but separate, applications. The Raw Crawler Service is responsible for coordinating crawls of digital collections sites and making the raw crawl data available. The Analyzed Crawl Service is responsible for extracting data and meaning from the raw crawl data to enable DPLA services. Building them as two independent applications can allow much of their development to happen in parallel.
Raw Crawler Service
The Raw Crawler Service uses the data collected by CAPS to discover digital collections to crawl. Crawls could fall into different categories. CAPS or other DPLA services could require a focused crawl of a collection to be triggered for timely data. Extensive crawls of digital collections sites could also be made.
The final product of the Raw Crawler Service is a store of the pages crawled along with technical metadata. Technical metadata would include when the page was last crawled and the HTTP headers returned with the request including the status code.
This data could be made available to external developers who want to conduct their own research or analysis on this slice of the Web. Both an API and data dump could be made available. Whether the API only provides for discovery of available raw crawl data or actually returns crawl data, is an open question. Because of the size of the corpus, it may be that the raw crawl data is made available in a lower cost way through cloud services. (See the Common Crawl for more on how this might work.)
The Raw Crawler Service would require an application to coordinate robots, a data store for raw crawl data, and a database for technical metadata about the crawl data. A Web application would also be needed to create the API service.
Analyzed Crawl Service
The DPLA could also provide an Analyzed Crawl Service. This service analyzes the raw crawl data to extract data and text from the raw crawl data. At this stage it can also begin to make connections across repositories. For various ways the DPLA can get to item-level data through crawl analysis, see Solving the Item-Level Problem on the Web. With crawls resulting in the full text of the page there is the the potential to provide rich item-level data without reliance on niche protocols.
The initial consumer of this service would be the DPLA. The resulting data could be used as the source metadata about collection pages underlying new DPLA aggregations and services. The data could be made available to external developers to create new aggregations, mashups, and services.
Conclusion
This high-level overview of a DPLA platform architecture is intended to spur discussion. There are many possibilities for what a DPLA technical architecture may look like. Presented here is a technical architecture which would enable the DPLA to function in the way that the Web works. Development could be scaffolded quickly and immediately begin to provide real benefits from the DPLA effort.
If the model set out here is not followed, the hope is that some of the principles here will remain in the DPLA effort. Allowing for content producers at all levels of technological sophistication to be part of a big tent DPLA effort is an important underlying principle. Technically, the DPLA can insure that at every level of the platform that the data and metadata it creates is made easily accessible for reuse.
Is there any merit to this kind of approach for digital library aggregations? Feedback welcome in the comments.
This text is copyright Jason Ronallo and licensed under a Creative Commons Attribution 3.0 Unported License.